Authors:Carter Slocum, Yicheng Zhang, Nael Abu-Ghazaleh and Jiasi Chen
Introduction
Imagine typing a password or sensitive corporate information in a virtual workspace, believing that your data is secure. However, an unseen threat lurks in the background—one that doesn’t need any special permissions to compromise your privacy. Welcome to the evolving world of Augmented Reality (AR) and Virtual Reality (VR), where your subtle head movements as you type can be exploited to reveal your private text. This emerging security risk is unveiled by TyPose, a groundbreaking system that can infer typed words or characters just by analyzing these minute head motions. With top-5 word classification accuracy reaching up to 92%, TyPose demonstrates how easily a malicious background application can breach your privacy. This blog explores the implications of this sophisticated attack and underscores the urgent need for robust security measures in our increasingly virtual world.
The TyPose Attack: How It Works
Let’s dive into how this stealthy attack unfolds. Imagine you’re using a VR headset, seamlessly switching between applications. Unbeknownst to you, one of these apps harbors malicious code. Here’s the process:
- Installation and Backgrounding: You install a seemingly harmless VR application. When you switch to another app, this malicious app slips into the background.
- Data Logging: Even though it’s not in focus, the malicious app continues to log data from your headset’s accelerometer and gyroscope—six degrees of freedom (6 DoF) data, to be precise.
- Sensitive Typing: As you type sensitive information—passwords, emails, or notes—the malicious app captures subtle head movements.
The attacker’s goal is to reconstruct what you’re typing with impressive accuracy. But how do they do it?
Challenges
TyPose faces several hurdles in transforming raw head movements into meaningful text. The first challenge is detecting when you’re typing. For instance, if you type a word and then make a noticeable head movement to hit the “search” button, this creates a distinct pattern in the data. However, most typing involves less obvious cues, like pressing the space bar.
Learning Patterns: TyPose overcomes this by employing a learning-based approach. By analyzing patterns in the data, it can segment your typing into individual words and characters. Even subtle head movements can reveal a lot. For example, slight downward glances to hit the space bar create detectable changes in the pitch of the headset.
- Decoding Typed Text: Once TyPose identifies the segments of your typing, it faces the task of deciphering the actual text. Remarkably, despite the minimal and almost invisible head movements during typing, the system’s sensors pick up enough variation to distinguish different words and characters. This means that, even with subtle head motions, TyPose can infer what you’re typing with surprising accuracy.
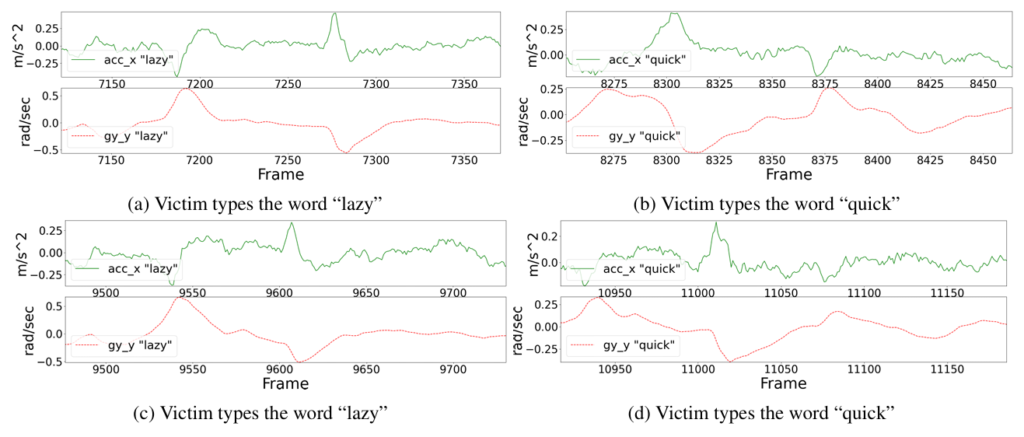
Figure 1: Example of a user’s head rotation and linear acceleration when typing the words “lazy” and “quick”, twice each. The traces are quite dissimilar across words, and somewhat dissimilar across trials of the same word.
TyPose’s Design: A Deep Dive
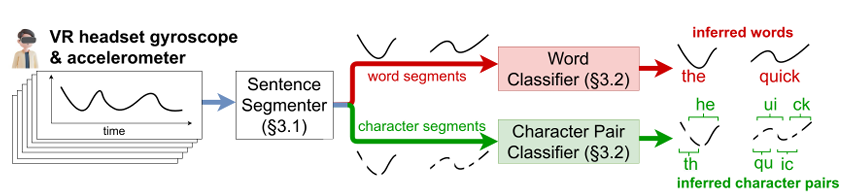
TyPose’s sophisticated system operates through two main modules: the Sentence Segmenter and the Word Classifier. Let’s break down how these modules work together to infer your typed text from subtle head movements.
Sentence Segmenter: Detecting When You’re Typing
The first challenge for TyPose is identifying when you are actually typing versus when you are pausing. This isn’t as simple as it sounds, given that the system only has access to your head movements, not the actual key presses.
To tackle this, TyPose employs two convolutional neural networks (CNNs). These networks are trained to segment sentences into individual words or characters by analyzing the patterns in the gyroscope and accelerometer data from your VR headset.
Think of it this way: when you type on a virtual keyboard, pressing the space bar or moving to a new word causes distinct patterns in your head’s motion. The Sentence Segmenter learns these patterns, even though they might be almost invisible to the naked eye. For example, if you nod slightly every time you press the space bar, the Segmenter can pick up on these subtle movements and mark them as word boundaries.
Word Classifier: Decoding the Typed Text
Once the Sentence Segmenter identifies the boundaries of words or characters, the Word Classifier steps in. This module takes the segmented data and translates it into probable words or character pairs using another CNN.
Imagine you typed “hello” and “world.” Although the head movements are subtle, they are consistent enough for the Word Classifier to recognize patterns. By training on vast amounts of data, the system can accurately infer these words from the motion data it receives.
Overcoming Challenges
Initially, TyPose tried using conventional time series segmentation techniques, but these proved inadequate. These methods couldn’t recognize the specific “motifs” or patterns in head movements that correspond to typing. Instead, TyPose treats segmentation as a binary classification problem—determining whether a particular moment is a boundary of a segment.
This approach has several advantages. For one, it doesn’t require knowledge about the exact layout or position of the virtual keyboard. Whether the keyboard moves or changes orientation, the system still performs well because it relies solely on the raw sensor data.
TyPose’s Design: Inside the Mechanism
Sentence Segmenter: Detecting Typing Boundaries
TyPose’s first task is pinpointing when you start and stop typing. This is achieved by the Sentence Segmenter, which processes windowed samples from the 6 DoF (Degrees of Freedom) time series data. It uses a convolutional neural network (CNN) to determine the probability that a given sample contains a boundary, such as a space bar press or any character key press.
Imagine the time series data as a 2D image where each “pixel” represents the linear acceleration or angular velocity at a specific moment. The CNN architecture, inspired by successful models in image and time series classification, comprises four convolutional layers. These layers extract patterns from the data and are followed by fully connected layers and a soft-max layer that outputs the probability of a boundary.
The Segmenter identifies segments by analyzing these probabilities and marking the boundaries of words or characters based on learned patterns in head movements.
Word Classifier: Decoding Typed Text
Once the Sentence Segmenter identifies potential word boundaries, the Word Classifier steps in. This module uses a similar CNN architecture but is designed to handle variable-length segments of text. It converts these segments into probable words or character pairs.
For instance, if the Segmenter identifies the boundaries of the word “hello,” the Word Classifier takes this segment and predicts the most likely word based on the head movement data.
The classifier adapts to different segment lengths by padding shorter samples with zeros, ensuring consistent input sizes for the CNN. The final fully connected layer’s size is adjusted based on the number of possible output classes—words or character pairs.
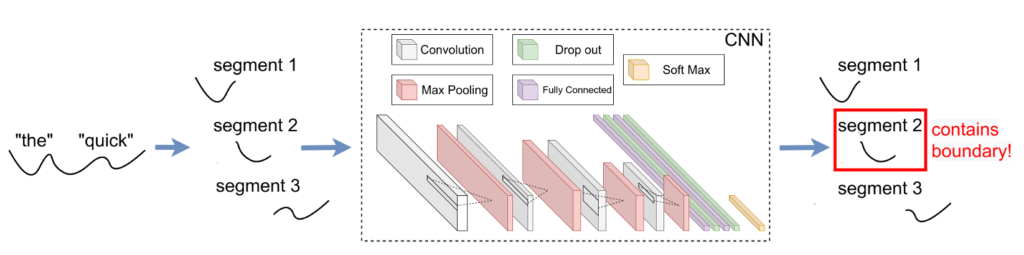
- Figure 2: Sentence segmenter design. The example shows finding the word boundaries in a sentence. The same design is used to find character boundaries in a word.
Putting It All Together
TyPose’s design showcases the power of machine learning in deciphering subtle patterns from complex data. By treating head movements as signals, it can accurately infer what you’re typing in a VR environment, revealing potential security vulnerabilities.
In summary, TyPose’s innovative approach consists of:
- Sentence Segmenter: Detects when typing starts and stops using CNNs to analyze head movement patterns.
- Word Classifier: Decodes the segmented data into words or characters, adapting to various input lengths and predicting based on learned patterns.
Possible Limitations
- A different user may have a different typing speed. He or she may not need to move his or her head while typing. What happens in that scenario?
- What happens when there is a noisy head movement (looking at the top, bottom, or side) involved while typing?
To learn more about this paper, you can check it out here.
Thank you all.